
مؤسسه آموزش عالي چهل ستون
عنوان پروژه:
وب کاوی در صنعت
پروژه کاردانی
رشته نرم افزار
ارائه شده به
گروه علمي كامپيوتر
تهيه كننده:
فائزه غفاری
تابستان 94
به نام خداوند بخشاينده مهربان
سپاسگذاری
و خداوند تبارک و تعالی خلقت را با حکمت سرشت و چون بارقه ای از دانایی بر انسان نثار کردن نیستی را به هستی کشاند ……..
پس والاترین درود و سپاس بر یگانه آفریدگاری که به من توفیق به انجام رساندن این پایان نامه را اعطا نمود
تجلی دانایی الهی در ضمیر انسان شد تا در معبد وجود آتشی صد رنگ بر افروزند.
پس شایسته است از سرکارخانم ریحانه گلکیش که با رهنمودهایشان مرا در پایان نامه یاری دادند کمال قدر شناسی را به عمل آورم.
تقدیم به:
در آغاز به تو میگویم که آغاز و پایان هر راهی.
که اوجم با تو بوده است و فرودم هم …
به تو میگویم سپاسی را که نه چندان شایسته لطف توست
تا بر من ببخشایی گستاخی کودکانه ام را
و میخواهم که با من بمانی تا ابد.چرا که چون تو دارم همه دارم
و به اذن تو و پس از برکت وجودت حاصل این تلاش نثار میگردد .
به مادر و پدرم که یاریشان خنکای نسیم سحرگاهان بوده در طول راهم
و در پایان از کمک تمام کسانی که دوستشان دارم وهمراهیام نمودندتشکر میکنم.
کلیه حقوق مترتب بر نتایج مطالعات، ابتکارات و نوآوریهای ناشی از تحقیق موضوع این پروژه متعلق به
مؤسسه آموزش عالی چهلستون است.
چکيده
با افزايش چشمگير حجم اطلاعات و توسعه وب، نياز به روش ها و تکنيک هايي که بتوانند امکان دستيابي کارا به دادهها و استخراج اطلاعات از آنها را فراهم کنند، بيش از پيش احساس مي شود. وب کاوي يکي از زمينه هاي تحقيقاتي است که با به کارگيري تکنيک هاي داده کاوي به کشف و استخراج خودکار اطلاعات از اسناد و سرويسهاي وب مي پردازد. در واقع وب کاوي، فرآيند کشف اطلاعات و دانش ناشناخته و مفيد از داده هاي وب مي باشد. روش هاي وب کاوي بر اساس آن که چه نوع داده اي را مورد کاوش قرار مي دهند، به سه دسته کاوش محتوای وب، کاوش ساختار وب و کاوش استفاده از وب تقسيم می شوند. طي اين گزارش پس از معرفی وب کاوي و بررسی مراحل آن، ارتباط وب کاوي با ساير زمينه هاي تحقيقاتي بررسي شده و به چالش ها، مشکلات و کاربردهای اين زمينه تحقيقاتي اشاره مي شود. همچنين هر يک از انواع وب کاوي به تفصيل مورد بررسي قرار مي گيرند که در این پروژه بیشتر به وب کاوی در صنعت می پردازم. براي اين منظور مدل ها، الگوريتم ها و کاربردهاي هر طبقه معرفي مي شوند.
فهرست مطالب
عنوان شماره صفحه
فصل اول:مقدمه
فصل دوم:داده کاوی
2-1-1 چه چيزی سبب پيدايش داده کاوی شده است؟ 7
2- 3 جایگاه داده کاوی در میان علوم مختلف 12
2-4 داده کاوی چه کارهایی نمی تواند انجام دهد؟ 14
2-5 داده کاوی و انبار داده ها 14
2-7 کاربرد یادگیری ماشین و آمار در داده کاوی 16
2-8 توصیف داده ها در داده کاوی 16
2-8-1 خلاصه سازی و به تصویر در آوردن داده ها 16
2-9 مدل های پیش بینی داده ها 18
2-10 مدل ها و الگوریتم های داده کاوی 19
2-10-3 Multivariate Adaptive Regression Splines(MARS) 24
2-10-5 K-nearest neibour and memory-based reansoning(MBR) 25
2-10-8 مدل افزودنی کلی (GAM) 28
2-12داده کاوی و مدیریت بهینه وب سایت ها 30
2-13دادهكاوي و مديريت دانش 31
فصل سوم: وب کاوی
3-3 وب کاوي و زمينه هاي تحقيقاتي مرتبط 34
3-3-2 وب کاوي و بازيابي اطلاعات 35
3-3-3 وب کاوي و استخراج اطلاعات 36
3-3-4 وب کاوي و يادگيري ماشين 37
3-6مشكلات ومحدوديت هاي وب كاوي در سايت هاي فارسي زبان 39
فصل چهارم: وب کاوی در صنعت
4-1-1وب کاوی در صنعت نفت، گاز و پتروشیمی 43
4-1-1-1 مهندسی مخازن/ اکتشاف 43
4-1-2 کاربرد های دانش داده کاوی در صنعت بیمه 45
4-1-3کاربردهای دانش داده کاوی در مدیریت شهری 46
4-1-4کاربردهای داده کاوی در صنعت بانکداری 47
مراجع و ماخذ لاتین و سایتهای اینترنتی 52
فهرست اشکال
عنوان شماره صفحه
شکل(2-1) داده کاوی به عنوان يک مرحله از فرآيند کشف دانش 8
شکل(2-2) سير تکاملی صنعت پايگاه داده 10
شکل (2-3) معماری يک نمونه سيستم داده کاوی 11
شکل (2-4) داده ها از انباره داه ها استخراج می گردند 14
شکل(2-5( داده ها از چند پایگاه داده استخراج شده اند 15
شكل(2-6) شبکه عصبی با یک لایه نهان 20
شكل(2-7) Wx,y وزن یال بین X و Y است. 21
مقدمه
مقدمه
با توسعه سيستم هاي اطلاعاتي، داده به يکي از منابع پراهميت سازمان ها مبدل گشته است. بنابراين روش ها و تکنيک هايي براي دستيابي کارا به داده، اشتراک داده، استخراج اطلاعات از داده و استفاده از اين اطلاعات، مورد نياز مي باشد. با ايجاد و گسترش وب و افزايش چشمگير حجم اطلاعات، نياز به اين روش ها و تکنيک ها بيش از پيش احساس مي شود. وب، محيطي وسيع، متنوع و پويا است که کاربران متعدد اسناد خود را در آن منتشر مي کنند. در حال حاضر بيش از دو بيليون صفحه در وب موجود است و اين تعداد با نرخ 3/7 ميليون صفحه در روز افزايش مييابد. با توجه به حجم وسيع اطلاعات در وب، مديريت آن با ابزارهاي سنتي تقريبا غير ممکن است و ابزارها و روش هايي نو براي مديريت آن مورد نياز است. به طور کلي کاربران وب در استفاده از آن با مشکلات زير روبرو هستند:
-
-
-
- يافتن اطلاعات مرتبط: يافتن اطلاعات مورد نياز در وب دشوار مي باشد. روش هاي سنتي بازيابي اطلاعات که براي جستجوي اطلاعات در پايگاه داده ها به کار مي روند، قابل استفاده در وب نميباشند وکاربران معمولا از موتورهاي جستجو که مهمترين و رايج ترين ابزار براييافتن اطلاعات در وب مي باشند، استفاده مي کنند. اين موتورها، يک پرس و جوي[1] مبتني بر کلمات کليدي از کاربر دريافت کرده و در پاسخ ليستي از اسناد مرتبط با پرس و جوي وي را که بر اساس ميزان ارتباط با اين پرس و جو مرتب شده اند، به وي ارائه مي کنند. اما موتورهاي جستجو داراي دو مشکل اصلي هستند. اولا دقت[2] موتورهاي جستجو پايين است، چراکه اين موتورها در پاسخ به يک پرس و جوي کاربر صدها يا هزاران سند را بازيابي مي کنند، در حالي که بسياري از اسناد بازيابي شده توسط آنها با نياز اطلاعاتي کاربر مرتبط نمي باشند. دوما ميزان فراخوان[3] اين موتورها کم مي باشد، به آن معني که قادر به بازيابي کليه اسناد مرتبط با نياز اطلاعاتي کاربر نيستند. چراکه حجم اسناد در وب بسيار زياد است و موتورهاي جستجو قادر به نگهداري اطلاعات کليه اسناد وب، در پايگاه داده هاي خود نمي باشند.
- ايجاد دانش جديد با استفاده از اطلاعات موجود در وب: اين مشکل در واقع بخشي از مشکل مطرح شده در قسمت قبل مي باشد. در حال حاضر اين سوال مطرح است که چگونه مي توان داده هاي فراوان موجود در وب را به دانشي قابل استفاده تبديل کرد، به طوري که يافتن اطلاعات مورد نياز در آن به سادگي صورت بگيرد. همچنين چگونه مي توان با استفاده از داده هاي وب به اطلاعات و دانشي جديد دست يافت.
- خصوصي سازي[4] اطلاعات: از آن جا که کاربران متفاوت هر يک درباره نوع و نحوه بازنمايي اطلاعات سليقه خاصي دارند،اين مسئله بايد توسط تامين کنندگان اطلاعات در وب مورد توجه قرار بگيرد. براي اين منظور با توجه به خواسته ها و تمايلات کاربران متفاوت، نحوه ارائه اطلاعات به آنها بايد سفارشي گردد.
-
-
تکنيک هاي وب کاوي[5]قادر به حل اين مشکلات مي باشند. دروب کاويبه صورت زير تعريف شده است:
وب کاوي به کارگيري تکنيک هاي داده کاوي[6] براي کشف و استخراج خودکار اطلاعات از اسناد و سرويس هاي وب مي باشد.
البته تکنيک هاي وب کاوي تنها ابزار موجود براي حل اين مشکلات نيستند. بلکه تکنيک هاي مختلفي از ساير زمينه هاي تحقيقاتي همچون پايگاه داده ها، بازيابي اطلاعات، پردازش زبان طبيعي قابل استفاده در اين زمينه مي باشند. همچنين تکنينک هاي وب کاوي مي توانند به صورت مستقيم يا غير مستقيم براي حل اين مشکلات به کار روند. منظور از رويکرد مستقيم آن است که کاربرد تکنيک هاي وب کاوي به صورت مستقيم مشکلات مطرح شده را حل مي نمايد. يک عامل گروه خبري که مرتبط بودن يک خبر به يک کاربر را تعيين مي کند، مثالي از اين رويکرد مي باشد. اما در رويکرد غير مستقيم، تکنيک هاي وب کاوي به عنوان بخشي از يک روش جامع تر که به حل اين مشکلات مي پردازد، مورد استفاده قرار مي گيرند.
با توجه به گسترش روز افزون حجم اطلاعات در وب و ارتباط وب کاوي با تجارت الکترونيکي، وب کاوي به يک زمينه تحقيقاتي وسيع مبدل گشته است. طي اين گزارش پس از بررسي مراحل وب کاوي،انواع آن معرفي مي شوند. سپس ارتباط وب کاوي با ساير زمينه هاي تحقيقاتي بررسي شده و به چالش ها و مشکلات اين زمينه تحقيقاتي اشاره مي شود. در ادامه هر يک از انواع وب کاوي به تفصيل مورد بررسي قرار مي گيرند. براي اين منظور مدل ها، الگوريتم ها و کاربردهاي هر طبقه معرفي مي شوند. در پايان نيز به برخي از نمونه کاربردهاي واقعي وب کاوي اشاره مي شود.
فصل دوم
داده کاوی
در دو دهه قبل توانايي های فنی بشر در برای توليد و جمع آوری دادهها به سرعت افزايش يافته است. عواملی نظير استفاده گسترده از بارکد برای توليدات تجاری، به خدمت گرفتن کامپيوتر در کسب و کار، علوم، خدمات دولتی و پيشرفت در وسائل جمع آوری داده، از اسکن کردن متون و تصاوير تا سيستمهای سنجش از دور ماهواره ای، در اين تغييرات نقش مهمی دارند .
بطور کلی استفاده همگانی از وب و اينترنت به عنوان يک سيستم اطلاع رسانی جهانی ما را مواجه با حجم زیادی از داده و اطلاعات میکند. اين رشد انفجاری در دادههای ذخيره شده، نياز مبرم وجود تکنولوژی های جديد و ابزارهای خودکاری را ايجاد کرده که به صورت هوشمند به انسان ياری رسانند تا اين حجم زياد داده را به اطلاعات و دانش تبديل کند: داده کاوی به عنوان يک راه حل برای اين مسائل مطرح مي باشد. در يک تعريف غير رسمی داده کاوی فرآيندی است، خودکار برای استخراج الگوهايی که دانش را بازنمايی مي کنند، که اين دانش به صورت ضمنی در پايگاه داده های عظيم، انباره داده[7] و ديگر مخازن بزرگ اطلاعات، ذخيره شده است. داده کاوی بطور همزمان از چندين رشته علمی بهره مي برد نظير: تکنولوژی پايگاه داده، هوش مصنوعی، يادگيری ماشين، شبکه های عصبی، آمار، شناسايی الگو، سيستم های مبتنی بر دانش[8]، حصول دانش[9]، بازيابی اطلاعات[10]، محاسبات سرعت بالا[11] و بازنمايی بصری داده[12] . داده کاوی در اواخر دهه 1980 پديدار گشته، در دهه 1990 گامهای بلندی در اين شاخه از علم برداشته شده و انتظار می رود در اين قرن به رشد و پيشرفت خود ادامه دهد .واژه های «داده کاوی» و «کشف دانش در پایگاه داده»[13] اغلب به صورت مترادف یکدیگر مورد استفاده قرار می گیرند. کشف دانش به عنوان يک فرآيند در شکل2-1 نشان داده شده است.
کشف دانش در پایگاه داده فرایند شناسایی درست، ساده، مفید، و نهایتا الگوها و مدلهای قابل فهم در داده ها می باشد. داده کاوی، مرحله ای از فرایند کشف دانش می باشد و شامل الگوریتمهای مخصوص داده کاوی است، بطوریکه، تحت محدودیتهای مؤثر محاسباتی قابل قبول، الگوها و یا مدلها را در داده کشف می کند . به بیان ساده تر، داده کاوی به فرایند استخراج دانش ناشناخته، درست، و بالقوه مفید از داده اطلاق می شود. تعریف دیگر اینست که، داده کاوی گونه ای از تکنیکها برای شناسایی اطلاعات و یا دانش تصمیم گیری از قطعات داده می باشد، به نحوی که با استخراج آنها، در حوزه های تصمیم گیری، پیش بینی، پیشگویی، و تخمین مورد استفاده قرار گیرند. داده ها اغلب حجیم ، اما بدون ارزش می باشند، داده به تنهایی قابل استفاده نیست، بلکه دانش نهفته در داده ها قابل استفاده می باشد. به این دلیل اغلب به داده کاوی، تحلیل داده ای ثانویه[14] گفته می شود.
2-1-1 چه چيزی سبب پيدايش داده کاوی شده است؟
اصلی ترين دليلی که باعث شد داده کاوی کانون توجهات در صنعت اطلاعات قرار بگيرد، مساله در دسترس بودن حجم وسيعی از داده ها و نياز شديد به اينکه از اين داده ها اطلاعات و دانش سودمند استخراج کنيم. اطلاعات و دانش بدست آمده در کاربردهای وسيعی از مديريت کسب و کار وکنترل توليد و تحليل بازار تا طراحی مهندسی و تحقيقات علمی مورد استفاده قرار می گيرد.
داده کاوی را می توان حاصل سير تکاملی طبيعی تکنولوژی اطلاعات دانست، که اين سير تکاملی ناشی از يک سير تکاملی در صنعت پايگاه داده می باشد، نظير عمليات: جمع آوری داده ها وايجاد پايگاه داده، مديريت داده و تحليل و فهم داده ها. در شکل 2-1 اين روند تکاملی در پايگاه های داده نشان داده شده است.
شکل(2-1) داده کاوی به عنوان يک مرحله از فرآيند کشف دانش
تکامل تکنولوژی پايگاه داده و استفاده فراوان آن در کاربردهای مختلف سبب جمع آوری حجم فراوانی داده شده است. اين داده های فراوان باعث ايجاد نياز برای ابزارهای قدرتمند برای تحليل دادهها گشته، زيرا در حال حاضر به لحاظ داده ثروتمند هستيم ولی دچار کمبود اطلاعات می باشيم.
ابزارهای داده کاوی داده ها را آناليز می کنند و الگوهای دادهای را کشف می کنند که می توان از آن در کاربردهايی نظير: تعيين استراتژی برای کسب و کار، پايگاه دانش[15] و تحقيقات علمی و پزشکی، استفاده کرد. شکاف موجود بين داده ها و اطلاعات سبب ايجاد نياز برای ابزارهای داده کاوی شده است تا داده های بی ارزش را به دانشی ارزشمند تبديل کنيم .
به طور ساده داده کاوی به معنای استخراج يا «معدن کاری[16]» دانش از مقدار زيادی داده خام است. البته اين نامگذاری برای اين فرآيند تا حدی نامناسب است، زيرا به طور مثال عمليات معدن کاری برای استخراج طلا از صخره و ماسه را طلا کاوی می ناميم، نه ماسه کاوی يا صخره کاوی، بنابراين بهتر بود به اين فرآيند نامی شبيه به «استخراج دانش از داده» می داديم که متاسفانه بسيار طولانی است. «دانش کاوی» به عنوان يک عبارت کوتاهتر به عنوان جايگزين، نمی تواند بيانگر تاکيد و اهميت بر معدن کاری مقدار زياد داده باشد. معدن کاری عبارتی است که بلافاصله انسان را به ياد فرآيندی مي اندازد که به دنبال يافتن مجموعه کوچکی از قطعات ارزشمند از حجم بسيار زيادی از مواد خام هستيم.
با توجه به مطالب عنوان شده، با اينکه اين فرآيند تا حدی دارای نامگذاری ناقص است ولی اين نامگذاری يعنی داده کاوی بسيار عموميت پيدا کرده است. البته اسامی ديگری نيز برای اين فرآيند پيشنهاد شده که بعضا بسياری متفاوت با واژه داده کاوی است، نظير: استخراج دانش از پايگاه داده، استخراج دانش[17]، آناليز داده / الگو، باستان شناسی داده[18]، و لايروبی داده ها[19].
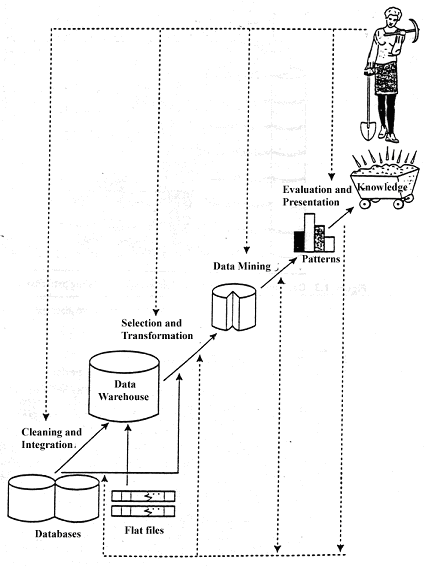
کشف دانش دارای مراحل تکراری زير است:
1- پاکسازی داده ها (از بين بردن نويز و ناسازگاری داده ها).
2- يکپارچه سازی داده ها (چندين منبع داده ترکيب می شوند).
3- انتخاب داده ها (داده های مرتبط با آناليزازپايگاه داده بازيابی می شوند).
4- تبديل کردن داده ها (تبديل داده ها به فرمی که مناسب برای داده کاوی باشد مثل خلاصهسازی و همسان سازی)
5- داده کاوی (فرايند اصلی که روالهای هوشمند برای استخراج الگوها از داده ها به کار گرفته ميشوند.)
6- ارزيابی الگو (برای مشخص کردن الگوهای صحيح و مورد نظربه وسيله معيارهای اندازه گيری)
7- ارائه دانش (يعنی نمايش بصری، تکنيکهای بازنمايي دانش برای ارائه دانش کشف شده به کاربر استفاده می شود).
شکل(2-2) سير تکاملی صنعت پايگاه داده
هر مرحله داده کاوی بايد با کاربر يا پايگاه دانش تعامل داشته باشد. الگوهای کشف شده به کاربر ارائه می شوند و در صورت خواست او به عنوان دانش به پايگاه دانش اضافه می شوند. توجه شود که بر طبق اين ديدگاه داده کاوی تنها يک مرحله از کل فرآيند است، البته به عنوان يک مرحله اساسی که الگوهای مخفی را آشکار می سازد. با توجه به مطالب عنوان شده، دراينجا تعريفی از داده کاوی ارائه می دهيم:
“داده کاوی عبارتست از فرآيند يافتن دانش از مقادير عظيم داده های ذخيره شده در پايگاه داده، انباره داده ويا ديگر مخازن اطلاعات”
بر اساس اين ديدگاه يک سيستم داده کاوی به طور نمونه دارای اجزاء اصلی زير است که شکل2-3 بيانگر معماری سيستم است.
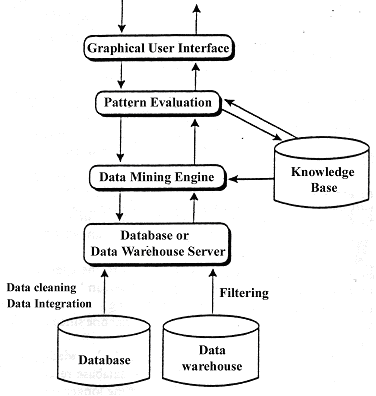
شکل (2-3) معماری يک نمونه سيستم داده کاوی
1- پايگاه داده، انباره داده يا ديگر مخازن اطلاعات: که از مجموعه ای از پايگاه داده ها، انباره داده، صفحه گسترده[20]، يا ديگر انواع مخازن اطلاعات. پاکسازی داده ها و تکنيکهای يکپارچه سازی روی اين داده ها انجام می شود.
2- سرويس دهنده پايگاه داده يا انباره داده: که مسئول بازيابی داده های مرتبط بر اساس نوع درخواست داده کاوی کاربر می باشد.
3- پايگاه دانش: اين پايگاه از دانش زمينه تشکيل شده تا به جستجو کمک کند، يا برای ارزيابی الگوهای يافته شده از آن استفاده می شود.
4- موتور داده کاوی : اين موتور جزء اصلی از سيستم داده کاوی است و به طور ايدآل شامل مجموعه ای از پيمانه هايی نظير توصيف ، تداعی، کلاسبندی، آناليزخوشه ها و آناليز تکامل وانحراف، است.
5- پيمانه ارزيابی الگو : اين جزء معيارهای جذابيت را به کار می بندد و با پيمانهء داده کاوی تعامل می کند بدينصورت که تمرکز آن بر جستجو بين الگوهای جذاب می باشد، و از يک حد آستانه جذابيت استفاده می کند تا الگوهای کشف شده را ارزيابی کند.
6- واسط کاربرگرافيکی : اين پيمانه بين کاربر و سيستم داده کاوی ارتباط برقرار می کند، به کاربر اجازه می دهد تا با سيستم داده کاوی از طريق پرس وجو ارتباط برقرار کند، اين جزء به کاربر اجازه می دهد تا شمای پايگاه داده يا انباره داده را مرور کرده، الگوهای يافته شده را ارزيابی کرده و الگوها را در فرمهای بصری گوناگون بازنمايی کند.
با انجام فرآيند داده کاوی، دانش، ارتباط يا اطلاعات سطح بالا از پايگاه داده استخراج می شود و قابل مرور از ديدگاههای مختلف خواهد بود. دانش کشف شده در سيستم های تصميم يار، کنترل فرآيند، مديريت اطلاعات و پردازش پرس وجو قابل استفاده خواهد بود.
بنابراين داده کاوی به عنوان يکی از شاخه های پيشرو در صنعت اطلاعات مورد توجه قرار گرفته و به عنوان يکی از نويد بخش ترين زمينه های توسعه بين رشته ای در صنعت اطلاعات است.
2- 3 جایگاه داده کاوی در میان علوم مختلف
ریشه های داده کاوی در میان سه خانواده از علوم، قابل پیگیری می باشد مهمترین این خانواده ها، آمار کلاسیک می باشد. بدون آمار، هیچ داده کاوی وجود نخواهد داشت، بطوریکه آمار، اساس اغلب تکنولوژی هایی می باشد که داده کاوی بر روی آنها بنا می شود. آمار کلاسیک مفاهیمی مانند تحلیل رگرسیون، توزیع استاندارد، انحراف استاندارد، واریانس، تحلیل خوشه، و فاصله های اطمینان را که همه این موارد برای مطالعه داده و ارتباط بین داده ها می باشد، را در بر می گیرد. مطمئنا تحلیل آماری کلاسیک نقش اساسی در تکنیکهای داده کاوی ایفا می کند.
دومین خانواده ای که داده کاوی به آن تعلق دارد هوش مصنوعی[21] می باشد. هوش مصنوعی که بر پایه روشهای ابتکاری می باشد و با آمار ضدیت دارد، تلاش دارد تا فرایندی مانند فکر انسان، را برای حل مسائل آماری بکار بندد. چون این رویکرد نیاز به توان محاسباتی بالایی دارد، تا اوایل دهه 1980 عملی نشد. هوش مصنوعی کاربردهای کمی را در حوزه های علمی و حکومتی پیدا کرد، اما نیاز به استفاده از کامپیوترهای بزرگ با عث شد همه افراد نتوانند از تکنیکهای ارائه شده استفاده کنند.
سومین خانواده داده کاوی، یادگیری ماشین[22] می باشد، که به مفهوم دقیقتر، اجتماع آمار و هوش مصنوعی می باشد. درحالیکه هوش مصنوعی نتوانست موفقیت تجاری کسب کند، یادگیری ماشین در بسیاری از موارد جایگزین آن گردید. از یادگیری ماشین به عنوان تحول هوش مصنوعی یاد شد، چون مخلوطی از روشهای ابتکاری هوش مصنوعی به همراه تحلیل آماری پیشرفته می باشد. یادگیری ماشین اجازه می دهد تا برنامه های کامپیوتری در مورد داده ای که آنها مطالعه می کنند، مانند برنامه هایی که تصمیمهای متفاوتی بر مبنای کیفیت داده مطالعه شده می گیرند، یادگیری داشته باشند و برای مفاهیم پایه ای آن از آمار استفاده می کنند و از الگوریتمها و روشهای ابتکاری هوش مصنوعی را برای رسیدن به هدف بهره می گیرند.
داده کاوی در بسیاری از جهات، سازگاری تکنیکهای یادگیری ماشین با کاربردهای تجاری است. بهترین توصیف از داده کاوی بوسیله اجتماع آمار، هوش مصنوعی و یادگیری ماشین بدست می آید. این تکنیکها سپس با کمک یکدیگر، برای مطالعه داده و پیدا کردن الگوهای نهفته در آنها استفاده می شوند.
بعضی از کاربردهای داده کاوی به شرح زیر است:
- کاربردهای معمول تجاری: از قبیل تحلیل و مدیریت بازار، تحلیل سبد بازار، بازاریابی هدف، فهم رفتار مشتری، تحلیل و مدیریت ریسک؛
- مدیریت و کشف فریب: کشف فریب تلفنی، کشف فریبهای بیمه ای و اتومبیل، کشف حقه های کارت اعتباری، کشف تراکنشهای مشکوک مالی (پولشویی)؛
- متن کاوی[23]: پالایش متن (نامه های الکترونیکی، گروههای خبری و غیره)؛
- پزشکی: کشف ارتباط علامت و بیماری، تحلیل آرایه های DNA ، تصاویر پزشکی؛
- ورزش: آمارهای ورزشی؛
- وب کاوی[24]: پیشنهاد صفحات مرتبط، بهبود ماشینهای جستجوگر یا شخصی سازی حرکت در وب سایت
2-4 داده کاوی چه کارهایی نمی تواند انجام دهد؟
داده کاوی فقط یک ابزار است و نه یک عصای جادویی. داده کاوی به این معنی نیست که شما راحت به کناری بنشینید و ابزارهای داده کاوی همه کار را انجام دهد.
داده کاوی نیاز به شناخت داده ها و ابزارهای تحلیل و افراد خبره در این زمینه ها را از بین نمی برد.
داده کاوی فقط به تحلیلگران برای پیدا کردن الگوها و روابط بین داده ها کمک می کند و در این مورد نیز روابطی که یافته می شود باید به وسیله داده های واقعی دوباره بررسی و تست گردد.
معمولا داده هایی که در داده کاوی مورد استفاده قرار می گیرند از یک انبار داده استخراج می گردند و در یک پایگاه داده یا مرکز داده ای ویژه برای داده کاوی قرار می گیرند.
اگر داده های انتخابی جزیی از انبار داده ها باشند بسیار مفید است چون بسیاری از اعمالی که برای ساختن انباره داده ها انجام می گیرد با اعمال مقدماتی داده کاوی مشترک است و در نتیجه نیاز به انجام مجدد این اعمال وجود ندارد ، از جمله این اعمال پاکسازی داده ها می باشد.
پایگاه داده مربوط به داده کاوی می تواند جزیی از سیستم انبار داده ها باشد و یا می تواند یک پایگاه داده جدا باشد.
شکل (2-4) داده ها از انباره داه ها استخراج می گردند
ولی با این حال وجود انباره داده ها برای انجام داده کاوی شرط لازم نیست و بدون آن هم اگر داده ها دریک یا چندین پایگاه داده باشند می توان داده کاوی را انجام دهیم و بدین منظور فقط کافیست داده ها را در یک پایگاه داده جمع آوری کنیم و اعمال جامعیت داده ها و پاکسازی داده ها را روی آن انجام دهیم. این پایگاه داده جدید مثل یک مرکز داده ای عمل می کند
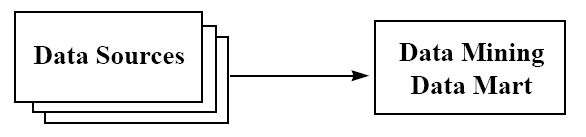
شکل(2-5( داده ها از چند پایگاه داده استخراج شده اند
بسیاری فکر می کنند که داده کاوی و OLAP دو چیز مشابه هستند در این بخش سعی می کنیم این مسئله را بررسی کنیم و همانطور که خواهیم دید این دو ابزار های کاملا متفاوت می باشند که می توانند همدیگر را تکمیل کنند.
OLAPجزیی از ابزارهای تصمیم گیری [25]می باشد.سیستم های سنتی گزارش گیری و پایگاه داده ای آنچه را که در پایگاه داده بود توضیح می دادند حال آنکه در OLAP هدف بررسی دلیل صحت یک فرضیه است.
بدین معنی که کاربر فرضیه ای در مورد داده ها و روابط بین آنها ارائه می کند و سپس به وسیله ابزار OLAP با انجام چند Query صحت آن فرضیه را بررسی می کند.
اما این روش برای هنگامی که داده ها بسیار حجیم بوده و تعداد پارامترها زیاد باشد نمیتواند مفید باشد چون حدس روابط بین داده ها کار سخت و بررسی صحت آن بسیار زمانبر خواهد بود.
تفاوت داده کاوی با OLAP در این است که داده کاوی برخلاف OLAP برای بررسی صحت یک الگوی فرضی استفاده نمی شود بلکه خود سعی می کند این الگوها را کشف کند.
درنتیجه داده کاوی و OLAP می توانند همدیگر را تکمیل کنند و تحلیل گر می تواند به وسیله ابزار OLAP یک سری اطلاعات کسب کند که در مرحله داده کاوی می تواند مفید باشد و همچنین الگوها و روابط کشف شده در مرحله داده کاوی می تواند درست نباشد که با اعمال تغییرات در آنها می توان به وسیله OLAP بیشتر بررسی شوند.
2-7 کاربرد یادگیری ماشین و آمار در داده کاوی
داده کاوی از پیشرفت هایی که در زمینه هوش مصنوعی و آمار رخ می دهد بهره می گیرد . هر دو این زمینه ها در مسائل شناسایی الگو و طبقه بندی داده ها کار می کنند و بالتبع در داده کاوی استفاده مستقیم خواهند داشت و هر دو گروه در شناخت و استفاده از شبکه های عصبی و درختهای تصمیم گیری فعال می باشند.
داده کاوی جانشین تکنیک های آماری سابق نمی باشد بلکه وارث آنها بوده و در واقع تغییر و گسترش تکنیک های سابق برای متناسب ساز ی آنها با حجم داده ها و مسائل امروزی می باشد. تکنیک های کلاسیک برای داده های محدود و مسائل ساده مناسب بوده اند حال آنکه با پیچیده شدن مسائل و رشد روزافزون داده ها نیاز به تغییر آنها کاملا طبیعی است.به عبارت دیگر داده کاوی ترکیب تکنیک های کلاسیک با الگوریتم های جدید مثل شبکه های عصبی و درخت تصمیم گیری می باشد.
مهمترین نکته این است که داده کاوی راهکاری است برای مسائل تجاری امروز به کمک تکنیک های آماری و هوش مصنوعی برای افراد حرفه ای که قصد دارند یک مدل پیش بینی ایجاد نمایند.
2-8 توصیف داده ها در داده کاوی
2-8-1 خلاصه سازی و به تصویر در آوردن داده ها
قبل از اینکه بتوان روی مجموعه ای از داده ها ،داده کاوی انجام بدهیم و یک مدل پیش بینی مناسب ابجاد کنیم ، باید بتوان داده ها را به خوبی شناخت که برا ی شروع این کار می توان از پارامترهایی مثل میانگین , انحراف معیار و…. استفاده کنیم.
ابزارهای تصویرسازی داده ها و گراف سازی برای شناخت داده ها بسیار مفید می باشند و نقش آنها در آماده سازی داده ها بسیار مفید و غیر قابل انکار است ، مثلا با استفاده از این ابزار می توان توزیع مقادیر مختلف داده ها را در یک نمودار مشاهده کرد و میزان داده های دارای خطا را به طور تقریبی حدس زد.
مهمترین مشکل این ابزار این است که معمولا تحلیل ها دارای تعداد زیادی پارامتر هستند که به هم مربوطند و باید رابطه این پارامترها را که چند بعدی می باشد در دو بعد نمایش دهند که این کار اگر هم عملی باشد برای استفاده از آنها نیاز به افراد خبره می باشد.
هدف از خوشه بندی این است که داده های موجود را به چند گروه تقسیم کنند و در این تقسیم بندی داده های گروه های مختلف باید حداکثر تفاوت ممکن را به هم داشته باشند و داده های موجود در یک گروه باید بسیار به هم شبیه باشند .
برخلاف کلاس بندی (که در ادامه خواهیم دید) در خوشه بندی ، گروه ها از قبل مشخص نمی باشند و همچنین معلوم نیست که بر حسب کدام خصوصیات گروه بندی صورت می گیرد. درنتیجه پس از انجام خوشه بندی باید یک فرد خبره خوشه های ایجاد شده را تفسیر کند و در بعضی مواقع لازم است که پس از بررسی خوشه ها بعضی از پارامترهایی که در خوشه بندی در نظر گرفته شده اند ولی بی ربط بوده یا اهمیت چندانی ندارند حذف شده و جریان خوشه بندی از اول صورت گیرد.
پس از اینکه داده ها به چند گروه منطقی و توجیه پذیر تقسیم شدند از این تقسیم بندی می توان برای کسب اطلاعات در مورد داده ها یا تقسیم داده ها جدید استفاده کنیم.
از مهمترین الگوریتم هایی که برای خوشه بندی استفاده می شوند می توان Kohnen و الگوریتم K-means را نام برد.
تحلیل داده ها یکی از روش های توصیف داده هاست که به کمک آن داده ها را بررسی کرده و روابط بین مقادیر موجود در بانک اطلاعاتی را کشف می کنیم.از مهمترین راههای تحلیل لینک کشف وابستگی و کشف ترتیب می باشد.
منظور از کشف وابستگی یافتن قوانینی در مورد مورادی است که با هم اتفاق می افتند مثلا اجناسی که در یک فروشگاه احتمال خرید همزمان آنها زیاد است.
کشف ترتیب نیر بسیار مشابه می باشد ولی پارامتر زمان نیز در آن دخیل می باشد.
وابستگی ها به صورت A->B نمایش داده می شوند که به A مقدم و به B موخر یا نتیجه گفته میشود. مثلا اگر یک قانون به صورت زیر داشته باشیم :
” اگر افراد چکش بخرند آنگاه آنها میخ خواهند خرید “
در این قانون مقدم خرید چکش و نتیجه خرید میخ می باشد.
در مسائل دسته بندی هدف شناسايی ويژگيهايی است که گروهی را که هر مورد به آن تعلق دارد را نشان دهند. از اين الگو میتوان هم برای فهم دادههای موجود و هم پيشبينی نحوه رفتار مواد جديد استفاده کرد.
دادهکاوی مدلهای دسته بندی را با بررسی دادههای دستهبندی شده قبلی ايجاد میکند و يک الگوی پيشبينی کننده را بصورت استقرايی میيابند. اين موارد موجود ممکن است از يک پايگاه داده تاريخی آمده باشند.
رگرسیون از مقادير موجود برای پيشبينی مقادير ديگر استفاده میکند. در سادهترين فرم، رگرسیون از تکنيکهای آماری استاندارد مانند linear رگرسیون استفاده میکند. متاسفانه، بسياری مسائل دنيای واقع تصويرخطی سادهای از مقادير قبلی نيستند. بناراين تکنيکهای پيچيدهتری (logistic رگرسیون، درختهای تصميم، يا شبکههای عصبی) ممکن است برای پيشبينی مورد نياز باشند.
انواع مدل يکسانی را میتوان هم برای رگرسیون و هم برای دسته بندی استفاده کرد. برای مثال الگوريتم درخت تصميم CART را میتوان هم برای ساخت درختهای دسته بندی و هم درختهای رگرسیون استفاده کرد. شبکههای عصبی را نيز میتوان برای هر دو مورد استفاده کرد.
پيشبينی های سری های زمانی مقادير ناشناخته آينده را براساس يک سری از پيشبينی گرهای متغير با زمان پيشبينی میکنند. و مانند رگرسیون، از نتايج دانسته شده برای راهنمايی پيشبينی خود استفاده میکنند. مدلها بايد خصوصيات متمايز زمان را در نظر گيرند و بويژه سلسلهمراتب دورهها را.
2-10 مدل ها و الگوریتم های داده کاوی
در این بخش قصد داریم مهمترین الگوریتم ها و مدل های داده کاوی را بررسی کنیم. بسیاری از محصولات تجاری داده کاوی از مجموعه از این الگوریتم ها استفاده می کنند و معمولا هر کدام آنها در یک بخش خاص قدرت دارند وبرای استفاده از یکی از آنها باید بررسی های لازم در جهت انتخاب متناسب ترین محصول توسط گروه متخصص در نظر گرفته شود.
نکته مهم دیگر این است که در بین این الگوریتم ها و مدل ها ، بهترین وجود ندارد و با توجه به دادهها و کارایی مورد نظر باید مدل انتخاب گردد.
شبکه های عصبی از پرکاربردترین و عملی ترین روش های مدل سازی مسائل پیچیده و بزرگ که شامل صدها متغیر هستند می باشد. شبکه های عصبی می توانند برای مسائل کلاس بندی (که خروجی یک کلاس است) یا مسائل رگرسیون (که خروجی یک مقدار عددی است) استفاده شوند.
هر شبکه عصبی شامل یک لایه ورودی [26]می باشد که هر گره در این لایه معادل یکی از متغیرهای پیش بینی می باشد. گره های موجود در لایه میانی وصل می شوند به تعدادی گره در لایه نهان[27]. هر گره ورودی به همه گره های لایه نهان وصل می شود.
گره های موجود در لایه نهان می توانند به گره های یک لایه نهان دیگر وصل شوند یا می توانند به لایه خروجی [28]وصل شوند.
لایه خروجی شامل یک یا چند متغیر خروجی می باشد.
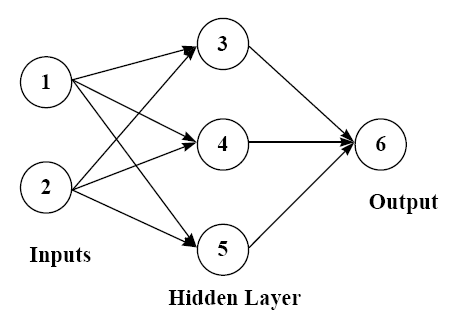
شكل(2-6) شبکه عصبی با یک لایه نهان
هر یال که بین نود های X,Y می باشد دارای یک وزن است که با Wx,y نمایش داده می شود. این وزن ها در محاسبات لایه های میانی استفاده می شوند و طرز استفاده آنها به این صورت است که هر نود در لایه های میانی (لایه های غیر از لایه اول) دارای چند ورودی از چند یال مختف می باشدکه همانطور که گفته شد هر کدام یک وزن خاص دارند.
هر نود لایه میانی میزان هر ورودی را در وزن یال مربوطه آن ضرب می کند و حاصل این ضرب ها را با هم جمع می کند و سپس یک تابع از پیش تعیین شده (تابع فعال سازی) روی این حاصل اعمال می کند و نتیجه را به عنوان خروجی به نودهای لایه بعد می دهد.
وزن یال ها پارامترهای ناشناخته ای هستند که توسط تابع آموزش [29]و داده های آموزشی که به سیستم داده می شود تعیین می گردند.
تعداد گره ها و تعداد لایه های نهان و نحوه وصل شدن گره ها به یکدیگر معماری (توپولوژی) شبکه عصبی را مشخص می کند. کاربر یا نرم افزاری که شبکه عصبی را طراحی می کند باید تعداد نودها ، تعداد لایه های نهان ، تابع فعال سازی و محدودیت های مربوط به وزن یال ها را مشخص کند.
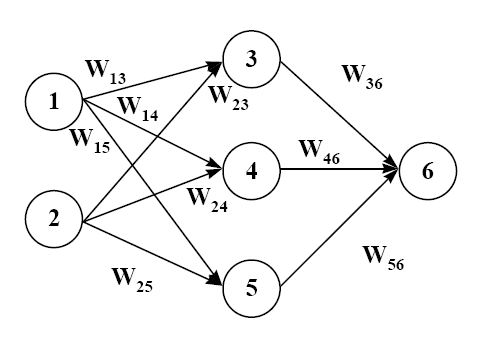
شكل(2-7) Wx,y وزن یال بین X و Y است.
از مهمترین انواع شبکه های عصبی Feed-Forward Backpropagation می باشد که در اینجا به اختصار آنرا توضیح می دهیم.
Feed-Forward به معنی این است که مقدار پارامتر خروجی براساس پارامترهای ورودی و یک سری وزن های اولیه تعیین می گردد. مقادیر ورودی با هم ترکیب شده و در لایه های نهان استفاده میشوند و مقادیر این لایه های نهان نیز برای محاسبه مقادیر خروجی ترکیب می شوند.
Backpropagation : خطای خروجی با مقایسه مقدار خروجی با مقدار مد نظر در داده های آزمایشی محاسبه می گردد و این مقدار برای تصحیح شبکه و تغییر وزن یال ها استفاده می گردد و از گره خروجی شروع شده و به عقب محاسبات ادامه می یابد.
این عمل برای هر رکورد موجود در بانک اطلاعاتی تکرار می گردد.
به هر بار اجرای این الگوریتم برای تمام داده های موجود در بانک یک دوره [30]گفته می شود. این دورهها آنقدر ادامه می یابد که دیگر مقدار خطا تغییر نکند.
از آنجایی که تعداد پارامترها در شبکه های عصبی زیاد می باشد محاسبات این شبکه ها می تواند وقت گیر باشد. ولی اگر این شبکه ها به مدت کافی اجرا گردند معمولا موفقیت آمیز خواهند بود. مشکل دیگری که ممکن است به وجود بیاید Overfitting می باشد و آن بدین صورت است که که شبکه فقط روی داده ها آموزشی خوب کار می کند و برای سایر مجموعه داده ها مناسب نمی باشد. برای رفع این مشکل ما باید بدانیم چه زمانی آموزش شبکه را متوقف کنیم.یکی از راه ها این است که شبکه را علاوه بر داده های آزمایشی روی داده های تست نیز مرتبا اجرا کنیم و جریان تغییر خطا را در آنها بررسی کنیم. اگر در این داده ها به جایی رسیدیم که میزان خطا رو به افزایش بود حتی اگر خطا در داده های آزمایشی همچنان رو به کاهش باشد آموزش را متوقف کنیم.
از آنجایی که پارامترهای شبکه های عصبی زیاد است یک خروجی خاص می تواند با مجموعه های مختلفی از مقادیر پارامترها ایجاد گردد درنتیجه این پارامترها مثل وزن یالها قابل تفسیر نبوده و معنی خاصی نمی دهند.
یکی از مهمترین فواید شبکه های عصبی قابلیت اجرای آنها روی کامپیوترهای موازی می باشد.
درختهای تصميم روشی برای نمايش يک سری از قوانين هستند که منتهی به يک رده يا مقدار میشوند. برای مثال، میخواهيم متقاضيان وام را به دارندگان ريسک اعتبار خوب و بد تقسيم کنيم. شکل يک درخت تصميم را که اين مسئله را حل میکد نشان میدهد و همه مؤلفههای اساسی يک يک درخت تصميم در آن نشان داده شده است : نود تصميم، شاخهها و برگها.
براساس الگوريتم، ممکن است دو يا تعداد بيشتری شاخه داشته باشد. برای مثال، CART درختانی با تنها دو شاخه در هر نود ايجاد میکند. هر شاخه منجر به نود تصميم ديگر يا يک نود برگ میشود. با پيمايش يک درخت تصميم از ريشه به پايين به يک مورد يک رده يا مقدار نسبت میدهيم. هر نود از دادههای يک مورد برای تصميمگيری درباره آن انشعاب استفاده میکند.
درختهای تصميم از طريق جداسازی متوالی دادهها به گروههای مجزا ساخته میشوند و هدف در اين فرآيند افزايش فاصله بين گروهها در هر جداسازی است.
يکی از تفاوتها بين متدهای ساخت درخت تصميم اينستکه اين فاصله چگونه اندازهگيری میشود. درختهای تصميمی که برای پيشبينی متغيرهای دستهای استفاده میشوند، درختهای دسته بندی ناميده میشوند زيرا نمونهها را در دستهها يا ردهها قرار میدهند. درختهای تصميمی که برای پيشبينی متغيرهای پيوسته استفاده میشوند درختهای رگرسیون ناميده میشوند.
هر مسير در درخت تصميم تا يک برگ معمولا قابل فهم است. از اين لحاظ يک درخت تصميم میتواند پيشبينیهای خود را توضيح دهد، که يک مزيت مهم است. با اين حال اين وضوح ممکن است گمراهکننده باشد. برای مثال، جداسازی های سخت در درختهای تصميم دقتی را نشان میدهند که کمتر در واقعيت نمود دارند. (چرا بايد کسی که حقوق او 400001 است از نظر ريسک اعتبار خوب باشد درحاليکه کسی که حقوقش 40000 است بد باشد. بعلاوه، از آنجاکه چندين درخت میتوانند دادههای مشابهای را با دقت مشابه نشان دهند، چه تفسيری ممکن است از قوانين شود؟
درختهای تصميم تعداد دفعات کمی از دادهها گذر میکنند(برای هر سطح درخت حداکثر يک مرتبه) و با متغيرهای پيشبينیکننده زياد بخوبی کار میکنند. درنتيجه، مدلها بسرعت ساخته میشوند، که آنها را برای مجموعهداده های بسيار مناسب میسازد. اگر به درخت اجازه دهيم بدون محدوديت رشد کند زمان ساخت بيشتری صرف میشود که غيرهوشمندانه است، اما مسئله مهمتر اينستکه با دادهها overfit میشوند. اندازه درختها را میتوان از طريق قوانين توقف کنترل کرد. يک قانون معمول توقف محدود کردن عمق رشد درخت است.
راه ديگر برای توقف هرس کردن درخت است. درخت میتواند تا اندازه نهايی گسترش يابد، سپس با استفاده از روشهای اکتشافی توکار يا با مداخله کاربر، درخت به کوچکترين اندازهای که دقت در آن از دست نرود کاهش میيابد.
يک اشکال معمول درختهای تصميم اينستکه آنها تقسيمکردن را براساس يک الگوريتم حريصانه انجام میدهند که در آن تصميمگيری اينکه براساس کدام متغير تقسيم انجام شود، اثرات اين تقسيم در تقسيمهای آينده را درنظر نمیگيرد.
بعلاوه الگوريتمهايی که برای تقسيم استفاده میشوند، معمولا تکمتغيری هستند: يعنی تنها يک متغير را در هر زمان در نظر میگيرند. درحاليکه اين يکی از دلايل ساخت سري مدل است، تشخيص رابطه بين متغيرهای پيشبينی کننده را سختتر میکند.
2-10-3 Multivariate Adaptive Regression Splines(MARS)
در ميانههای دهه 80 يکی از مخترعين CART ، ـJerome H. Friedman، متدی را برای برطرفکردن اين کاستیها توسعه داد.
کاستیهای اساسی که او قصد برطرف کردن آنها را داشت عبارتند از:
- پيشبينی های غيرپيوسته( تقسيم سخت)
- وابستگی همه تقسيمها به تقسيمهای قبلی
به اين دليل او الگوريتم MARS را توسعه داد. ايده اصلی MARS نسبتا ساده است، درحاليکه خود الگوريتم نسبتا پيچيده است. بسيار ساده ايده عبارت است از :
- جايگزينی انشعابهای غيرپيوسته با گذر های پيوسته که توسط يک جفت از خطهای مستقيم مدل میشوند. در انتهای فرآيند ساخت مدل، خطوط مستقيم در هر نود با يک تابع بسيار هموار که spline ناميده میشود جايگزين میشوند.
- عدم نياز به اينکه تقسيمهای جديد وابسته به تقسيمهای قديمی باشند.
متأسفانه اين به معنی اينست که MARS ساختار درختی CART را ندارد و نمیتواند قوانينی را ايجاد کند. از طرف ديگر، MARS به صورت خودکار مهمترين متغيرهای پيشبينی کننده و همچنين تعامل ميان آنها را میيابد. MARS همچنين وابستگی ميان پاسخ و هر پيشبينی کننده را معين میکند. نتيجه ابزار رگرسيون اتوماتيک، خودکار و step-wise است.
MARS، مانند بيشتر الگوريتمهای شبکههای عصبی و درخت تصميم، تمايل به overfit شدن برای دادههای آموزشدهنده دارد. که میتوان آنرا به دو طريق درست کرد. اول اينکه، cross validation بصورت دستی انجام شود و الگوريتم برای توليد پيشبينی خوب روی مجوعه تست تنظيم شود. دوم اينکه، پارامترهای تنظيم متفاوتی در خود الگوريتم وجود دارد که cross validation درونی را هدايت میکند.
استنتاج قوانين متدی برای توليد مجموعهای از قوانين است که موارد را دستهبندی میکند. اگرچه درختهای تصميم میتوانند مجموعهای از قوانين را ايجاد کند، متدهای استنتاج قوانين مجموعهای از قوانين مستقل را ايجاد میکند. که لزوما يک درخت را ايجاد نمیکنند. از آنجا که استنتاجگر قوانين اجباری به تقسيم در هر سطح ندارد، و میتواند به آينده بنگرد، قادر است الگوهای متفاوت و گاها بهتری برای ردهبندی بيابد. برخلاف درختان، قوانين ايجاد شده ممکن است همه موارد ممکن را نپوشاند. همچني« برخلاف درختان، قوانين ممکن است در پيشبينی متعارض باشند، که در هر مورد بايد قانونی را برای دنبال کردن انتخاب کرد. يک روش برای حل اين تعارضات انتصاب يک ميزان اطمينان به هر قانون است و استفاده از قانونی است که ميزان اطمينان بالاتری دارد.
2-10-5 K-nearest neibour and memory-based reansoning(MBR)
هنگام تلاش برای حل مسائل جديد، افراد معمولا به راهحل های مسائل مشابه که قبلا حل شدهاند مراجعه میکنند. K-nearest neighbor(k-NN) يک تکنيک دستهبندی است که از نسخهای از اين متد استفاده میکند. در اين روش تصميمگيری اينکه يک مورد جديد در کدام دسته قرار گيرد با بررسی تعدادی(k) از شبيهترين موارد يا همسايهها انجام میشود. تعداد موارد برای هر کلاس شمرده میشوند، و مورد جديد به دستهای که تعداد بيشتری از همسايهها به آن تعلق دارند نسبت داده میشود.
محدوده همسایگی (بیستر همسایه ها در دسته X قرار گرفته اند)
اولين مورد برای بکاربردن k-NN يافتن معياری برای فاصله بين صفات در دادهها و محاسبه آن است. در حاليکه اين عمل برای دادههای عددی آسان است، متغيرهای دستهای نياز به برخورد خاصی دارند. هنگامیکه فاصله بين مواد مختلف را توانستيم اندازه گيريم، میتوانيم از مجموعه مواردی که قبلا دستهبندی شدهاند را بعنوان پايه دستهبندی موارد جديد استفاده کنيم، فاصله همسايگی را تعيين کنيم، و تعيين کينم که خود همسايهها را چگونه بشماريم.
K-NN بار محاسباتی زيادی را روی کامپيوتر قرار میدهد زيرا زمان محاسبه بصورت فاکتوريلی از تمام نقاط افزايش میيابد. درحاليکه بکابردن درخت تصميم يا شبکه عصبی برای يک مورد جديد فرايند سريعی است، K-NN نياز به محاسبه جديدی برای هر مورد جديد دارد. برای افزايش سرعت K-NN معمولا تمام دادهها در حافظه نگهداری میشوند.
فهم مدلهای K-NN هنگاميکه تعداد متغيرهای پيشبينی کننده کم است بسيار ساده است. آنها همچنين برای ساخت مدلهای شامل انواع داده غير استاندارد هستند، مانند متن بسيار مفيدند. تنها نياز برای انواع داده جديد وجود معيار مناسب است.
رگرسیون منطقی یک حالت عمومی تر از رگرسیون خطی می باشد.قبلا این روش برای پیش بینی مقادیر باینری یا متغیرهای دارای چند مقدار گسسته (کلاس) استفاده می شد. از آنجایی که مقادیر مورد نظر برای پیش بینی مقادیر گسسته می باشند نمی توان آنرا به روش رگرسیون خطی مدلسازی کرد برای این منظور این متغیرهای گسسته را به روشی تبدیل به متغیر عددی و پیوسته می کنیم وبرای این منظور مقدار لگاریتم احتمال متغیر مربوطه را در نظر می گیریم و برای این منظور احتمال پیشامد را بدین صورت در نظر می گیریم:
احتمال اتفاق نیفتادن پیشامد/ احتمال اتفاق افتادن پیشامد و تفسیر این نسبت مانند تفسیری است که در بسیاری از مکالمات روزمره در مورد مسابقات یا شرط بندی ها یه موارد مشابه به کار می رود .مثلا وقتی می گوییم شانس بردن یک تیم در مسابقه 3 به 1 است در واقع از همین نسبت استفاده کرده و معنی آن این است که احتمال برد آن تیم 75% است.
وقتی که ما موفق شدیم لگاریتم احتمال مورد نظر را بدست آوریم با اعمال لگاریتم معکوس می توان نسبت مورد نظر و از روی آن کلاس مورد نظر را مشخص نمود.
این روش از قدیمی ترین روش های ریاضی وار گروه بندی داده ها می باشد که برای اولین بار در سال 1936 توسط فیشر استفاده گردید. روش کار بدین صورت است که داده ها را مانند داده های چند بعدی بررسی کرده و بین داده ها مرزهایی ایجاد می کنند (برای داده ها دو بعدی خط جدا کننده، برای داده های سه بعدی سطح جدا کننده و ..) که این مرزها مشخص کننده کلاس های مختلف می باشند و بعد برای مشخص کردن کلاس مربوط به داده های جدید فقط باید محل قرارگیری آن را مشخص کنیم.
این روش از ساده ترین و قابل رشدترین روش های کلاس بندی می باشد که در گذشته بسیار استفاده می شد.
این روش به سه دلیل محبوبیت خود را از دست داد :اول اینکه این روش فرض می کند همه متغیرهای پیش بینی به صورت نرمال توزیع شده اند که در بسیاری از موارد صحت ندارد . دوم اینکه داده هایی که به صورت عددی نمی باشند مثل رنگها در این روش قابل استفاده نمی باشند. سوم اینکه در این روش فرض می شود که مرزهای جدا کننده داده ها به صورت اشکال هندسی خطی مثل خط یا سطح می باشند حال اینکه این فرض همیشه صحت ندارد.
نسخه های اخیر تحلیل تفکیکی بعضی از این مشکلات را رفع کرده اند به این طریق اجازه می دهند مرزهای جدا کننده بیشتر از درجه 2 نیز باشند که باعث بهبود کارایی و حساسیت در بسیاری از موارد می گردد.
این روش ها در واقع بسطی بر روش های رگرسیون خطی و رگرسیون منطقی می باشند. به این دلیل به این روش افزودنی می گویند که فرض می کنیم می توانیم مدل را به صورت مجموع چند تابع غیر خطی (هر تابع برای یک متغیر پیش بینی کننده) بنویسیم. GAM می تواند هم به منظور رگرسیون و هم به منظور کلاس بندی داده ها استفاده گردد. این ویژگی غیر خطی بودن توابع باعث می شود که این روش نسبت به روشهای رگرسیون خطی بهتر باشد.
در این روش ها مبنی کار این است که الگوریتم پیش بینی را چندین بار و هر بار با داده های آموزشی متفاوت (که با توجه به اجرای قبلی انتخاب می شوند) اجرا کنیم و در نهایت آن جوابی که بیشتر تکرار شده را انتخاب کنیم. این روش اگر چه وقت گیر است ولی جواب های آن مطمئن تر خواهند بود. این روش اولین بار در سال 1996 استفاده شد و در این روزها با توجه به افزایش قدرت محاسباتی کامپیوترها بر مقبولیت آن افزوده گشته است.
هدف دادهکاوی توليد دانش جديدی است که کاربر بتواند از آن استفاده کند. اين هدف با ساخت مدلی از دنیای واقع براساس دادههای جمعآوری شده از منابع متفاوت بدست میآيد. نتيجه ساخت اين مدل توصيفی از الگوها و روابط دادههاست که میتوان آنرا برای پيشبينی استفاده کرد. سلسه انتخابهايی که قبل از آغاز بايد انجام شود به اين شرح است:
- هدف تجاری
- نوع پيشبینی
- نوع مدل
- الگوريتم
- محصول
در بالاترين سطح هدف تجاری قرار دارد: هف نهايی از کاوش دادهها چيست؟ برای مثال، جستجوی الگوها در دادهها ممکن است برای حفظ مشتریهای خوب باشد، که ممکن است مدلی برای سودبخشی مشتریها و مدل دومی برای شناسايی مشتریهايی که ممکن از دست دهيم میسازيم. اطلاع از اهداف و نيازهای سازمان ما را در فرموله کردن هدف سازمان ياری میرساند.
مرحله بعدی تصميمگيری درباره نوع پيشبينی مناسب است: دسته بندی ، پيشبينی اينکه يک مورد در کدام گروه يا رده قرار میگيرد يا رگرسیون، پيشبينی اينکه يک متغير عددی چه مقداری خواهد داشت.
مرحله بعدی انتخاب نوع مدل است: يک شبکه عصبی برای انجام رگرسیون ،و يک درخت تصميم برای دسته بندی. همچنين روشهای مرسوم آماری برای مانند logistic رگرسیون، discriminant analysis، و يا مدلهای خطی عمومی وجود دارد.
الگوريتمهای بسياری برای ساخت مدلها وجود دارد. میتوان يک شبکه عصبی را با backpropagation، يا توابع radial bias ساخت. برای درخت تصميم، میتوان از ميان CART، C5.0، Quest، و يا CHAID انتخاب کرد.
هنگام انتخاب يک محصول دادهکاوی، بايد آگاه بود که معمولا پيادهسازيهای متفاوتی از يک الگوريتم دارند. اين تفاوتهای پيادهسازی میتواند بر ويژگيهای عملياتی مانند استفاده از حافظه و ذخيره داده و همچنين ويژگيهای کارايی مانند سرعت و دقت اثر گذارند.
در مدلهای پيشگويانه، مقادير يا ردههايی که ما پيشبينی میکنيم متغيرهای پاسخ، وابسته، يا هدف ناميده میشوند. مقاديری که برای پيشبينی استفاده میشوند متغيرهای مستقل يا پيشبينیکننده ناميده میشوند.
مدلهای پيشگويانه با استفاده از دادههايی که مقادير متغيرهای پاسخ برای آنها از قبل دانسته شده است ساخته يا آموزش داده میشوند. اين نحوه آموزش supervised learning ناميده میشود، زيرا که مقادير محاسبه شده يا تخمينزده شده با نتايج معلومی مقايسه میشوند.( در مقابل، تکنيکهای توصيفی مانند clustering، unsupervised learning ناميده میشوند زيرا که هيچ نتيجه از پيش معلومی برای راهنمایی الگوريتم وجود ندارد.)
2-12داده کاوی و مدیریت بهینه وب سایت ها
هر سایت اینترنتی بر اساس حجم فعالیت خود برای نگهداری به افراد مختلفی که آشنا به امور فنی و اجرایی باشند نیاز دارد. مدیر سایت به عنوان شخصی که تنظیم کننده و هماهنگ کننده تمام این افراد است باید برای هر کدام از بخشهای سایت از قبیل گرافیک، محتوا، امور فنی، بازاریابی و… برنامههای مختلفی را تهیه و برای اجرا در اختیار همکاران خود قرار دهد. این برنامه ها می توانند شامل برنامه های روزانه، هفتگی و ماهانه باشند. تمامی این برنامه ها در راستای یک هدف کلی و نهایی به انجام می رسند و آن هم بالا رفتن کارایی اقتصادی سایت است.
سایت ها زمانی می توانند خود را در سطح اقتصادی اطمینان بخشی قرار دهند که از بازدیدکنندگان و کاربران و قابل توجهی برخوردار باشند. برای این کار مدیر سایت سعی می کند مطالعه و تحقیق گسترده ای بر روی عوامل و ابزارهای افزایش دهنده تعداد کاربران سایت انجام دهد و از این طریق در واقع به مطالعه شرایط و موقعیت خود در بازار مجازی اینترنت می پردازد. به عنوان مثال وی در مورد رنگ های به کار رفته در سایت، لوگو و سایر قطعات گرافیکی سایت، متن های به کار رفته و بسیاری دیگر از مسائل مرتبط با سایت به بررسی و مطالعه می پردازد.
یکی از روش ها و راهکارهایی که کمک بسیار زیادی برای بهتر شدن فرآیند مدیریت وب سایت ها می کند استفاده از گزارش ها و تحلیل های آماری است. مدیران سایت ها و مدیران بازایابی شرکت ها با استفاده از گزارش های به دست آمده از فعالیت سایت اینترنتی میتوانند شناخت خوبی از موقعیت و تاثیر فعالیت های خود پیدا کنند و از این طریق نقاط ضعف و قوت سایت را به راحتی شناسایی و برای حل و تقویت آنها تغییرات لازم را در سایت اعمال نمایند و به برنامه های آینده و حتی استراتژی های سایت جهت ببخشند.
اگر چه دانش به طور انحصاري محصول فناوري اطلاعات نيست، ولي فناوري اطلاعات به طور لاينفكي در ايجاد دانش و فرآيند مديريت دانش از سال هاي اول مشاركت داشته است. امروزه مديريت دانش از مسئوليت هاي فناوري اطلاعات به شمار ميرود. زيرا در جمعآوري، تبديل دانش و انتقال دادهها، اطلاعات و دانش نقش كليدي دارد.
از منظر مديريت دانش، هدف دادهكاوي، كشف دانش سازماني پنهان در اطلاعات خام است. اينگونه نيست كه هر بينش حاصل از دادهكاوي دانش ميسازد، بلكه در عوض بسياري از نتايج به دست آمده، اطلاعات مديريت، يا هوش سازماني است. مثلاً در سازمانهاي تجاري، دانش با ارزش
مورد مشتري، محصول و بازار را ميتوان از طريق دادهكاوي به دست آورد. دادهكاوي ابزار مفيدي براي مديران دانش است كه كشف را با تحليل تلفيق ميكنند. تلفيقي كه اغلب منجر به ايجاد دانش ميشود.
فصل سوم
وب کاوی
وب کاوی کاربردی از تکنيکهای داده کاوی است که به صورت خودکار اطلاعات را از مستندات وب و سرويسها استخراج و کشف می کند. وب کاوی اغلب به بازيابی و استخراج اطلاعات وابسته است، در حاليکه کشف اطلاعات يا وب کاوی بازيابی و استخراج اطلاعات نيست. هسته اصلی موتورهای جستجو از معماری سيستم های بازيابی اطلاعات سرچشمه می گيرد. ماهيت پويای اطلاعات در شبکه وب باعث ايجاد تغييرات اساسی در ساختار اوليه در موتورهای جستجو شده است. در سيستم های بازيابی اطلاعات، اسناد و مدارک توسط اشخاص جمع آوری می شدند و در اختيار سيستم قرار می گرفتند، در حالی که در موتورهای جستجو وظيفه جمع آوری اطلاعات به عهده خود موتور جستجو است.
علاوه بر آن به علت تغييرات صفحات وب، موتور جستجو وظيفه به روزرسانی اطلاعات جمع آوری شده را نيز خواهد داشت. يکی از مهمترين مسائل در طراحی موتورهای جستجو مساله کارائی و بازده بالای موتور جستجو است. حجم بالای اطلاعات موجود در شبکه وب و تغييرات سريع اطلاعات در اين شبکه (از قبيل اضافه شدن صفحات جديد، حذف شدن برخی از صفحات و تغير محتويات صفحات) حساسيت اين امر را بسيار زياد می کند. به عنوان مثال سرعت جمع آوری و سازماندهی اسناد در پايگاه دانش موتور جستجو، بايد بيشتر از نرخ تغييرات شبکه وب باشد. دراين مقاله به بررسی ساختار وب کاویپرداخته می شود.
وب کاوي شامل چهار مرحله اصلي مي باشد:
- پيدا کردن منبع: اين مرحله شامل بازيابي اسناد وب مورد نظر مي باشد.
- انتخاب اطلاعات و پيش پردازش: در اين مرحله به صورت خودکار اطلاعات خاصي از اسناد بازيابي شده، انتخاب و پيش پردازش مي شوند.
- تعميم[31]: در اين مرحله به صورت خودکار الگوهاي عام در يک يا چندين سايت وب کشف مي شود.
- تحليل: در اين مرحله الگوهاي به دست آمده در مرحله قبل اعتبار سنجي[32] و تفسير مي شوند.
در مرحله اول داده ها از منابع موجود در وب مانند خبرنامه هاي الکترونيکي، گروه هاي خبري، اسناد HTML، پايگاه داده هاي متني بازيابي مي شوند. مرحله انتخاب و پيش پردازش شامل هر گونه فرآيند تبديل داده هاي بازيابي شده در مرحله قبل مي باشد. اين پيش پردازش مي تواند کاهش کلمات به ريشه آنها[33]، حذف کلمات زائد[34]، پيدا کردن عبارات موجود در متن و تبديل بازنمايي داده ها به قالب رابطه اييا منطق مرتبه اول باشد. در مرحله سوم از تکنيک هاي داده کاوي و يادگيري ماشين براي تعميم استفاده مي شود. همچنين بايد توجه داشت که کاربران نقش مهمي در فرآيند استخراج اطلاعات و دانش از وب ايفا مي کنند. اين نکته به ويژه در مرحله چهارم از اهميت بسزايي برخوردار است.
به اين ترتيب وب کاوي، فرآيند کشف اطلاعات و دانش ناشناخته و مفيد از داده هاي وب مي باشد. اين فرآيند به طور ضمني شامل فرآيند کشف دانش در پايگاه داده ها(KDD[35]) نيز مي شود. در واقع وب کاوي گونه توسعه يافته KDD است که بر روي داده هاي وب عمل مي کند.
3-3 وب کاوي و زمينه هاي تحقيقاتي مرتبط
وب کاوي با زمينه هاي مختلف تحقيقاتي علوم کامپيوتر همچون داده کاوي، پايگاه داده، بازيابي اطلاعات، هوش مصنوعي، يادگيري ماشين، پردازش زبان طبيعي، استخراج اطلاعات، انبار داده ها[36]، طراحي واسط کاربر در ارتباط تنگاتنگ است.
در اين بخش ارتباط اين زمينه تحقيقاتي با برخي از زمينه هاي مرتبط بررسي مي شود.
وب کاوي و داده کاوي ارتباط بسيار نزديکي با يکديگر دارند. داده کاوي فرآيند ارائه پرسوجوها و استخراج الگوها و اطلاعات مفيد و ناشناخته از داده هايي است که معمولا در پايگاه داده ها ذخيره شده اند. در واقع بسياري از تکنيک هاي داده کاوي قابل استفاده در وب کاوي هستند. اما حوزه وب کاوي وسيع تر از داده کاوي است و اين دو زمينه تحقيقاتي در جنبه هاي مختلفي از يکديگر متفاوتند که برخي از آنها عبارتند از:
- در داده کاوي، داده ها ساخت يافته هستند و معمولا در پايگاه داده ها وجود دارند. اما در وب،داده ها عموما غير ساخت يافته هستند.
- جمع آوري و مديريت داده ها در وب دشوار است.
- داده ها در وب تنها شامل محتواي مستندات و صفحات وب نيستند. بلکه در وب دو نوع داده اصلي ديگر نيز براي کاوش مورد استفاده قرار مي گيرند. نوع اول، اطلاعات ساختاري وب است که منظور از آن پيوندهاي بين صفحات وب مي باشد. نوع دومنيز، اطلاعات مربوط به نحوه استفاده کاربران از وب است. در واقع تحليل رفتار کاربر در استفاده از وب، ترجيحات و علايق وي درباره نوع و قالب اطلاعات، بخش مهمي از وب کاوي است. در داده کاوي اين دو نوع از داده وجود ندارند.
- مسئله ديگري که در وب کاوي مطرح است، حفظ حريم کاربران[37] است. تکنيک هاي داده کاوي معمولا در يک محيط بسته به کار مي روند. در حالي که تکنيک هاي وب کاوي در محيط باز وب انجام مي شوند. بنابراين بايد تضمين شود، اطلاعات شخصي و خصوصي کاربران مورد سوء استفاده قرار نمي گيرند.
3-3-2 وب کاوي و بازيابي اطلاعات
بعضي محققين معتقدند که کشف منبع يا سند (بازيابي اطلاعات) در وب، نمونه اي از وب کاوي است و برخي وب کاوي را مرتبط با بازيابي اطلاعات هوشمند مي دانند. منظور از بازيابي اطلاعات، بازيابي خودکار اسناد مرتبط و در عين حال بازيابي کمترين حد ممکن از اسناد غير مرتبط مي باشد. اهداف اصلي بازيابي اطلاعات شاخص گذاري[38] متون و جستجو براي اسناد مرتبط در يک مجموعه مي باشد. در حال حاضر تحقيقات در زمينه بازيابي اطلاعات شامل مدلسازي، طبقه بندي[39] اسناد، واسط هاي کاربري، تصوير سازي داده[40]، جداسازي[41] و … مي باشد. آنچه در اين ميان مي تواند به عنوان نمونه اي از وب کاوي در نظر گرفته شود، طبقه بندي اسناد است که در شاخص گذاري مورد استفاده قرار مي گيرد. با چنين ديدگاهي وب کاوي به بخشي از فرآيند بازيابي اطلاعات مبدل مي گردد.
3-3-3 وب کاوي و استخراج اطلاعات
هدف از استخراج اطلاعات تبديل مجموعه اي از اسناد به اطلاعات خلاصه شده و تحليل شده ميباشد. در حالي که تمرکز اصلي در بازيابي اطلاعات بر انتخاب اسناد مرتبط است، استخراج اطلاعات بر استخراج وقايع مرتبط از اسناد تکيه دارد. همچنين در استخراج اطلاعات، ساختار يا بازنمايييک سند مد نظر قرار مي گيرد، در حالي که در بازيابي اطلاعات، يک سند مجموعه اي نامرتب از کلمات است.
ساخت يک سيستم استخراج اطلاعات براي محيط پويا و متنوعي چون وب امکان پذير نيست و بيشتر سيستم هاي ايجاد شده بر سايت هاي وب خاصي متمرکز مي شوند. برخي ديگر از سيستم هاي استخراج اطلاعات از تکنيک هاييادگيري ماشين و داده کاوي براييادگيري قوانين و الگوهاي استخراج استفاده مي کنند. با اين ديدگاه، وب کاوي بخشي از فرآيند استخراج اطلاعات مي باشد.
البته ديدگاه هاي ديگري درباره ارتباط اين دو وجود دارد. برخي معتقدند استخراج اطلاعات گونه اي از مرحله پيش پردازش (مرحله بعد از بازيابي اطلاعات و قبل از اعمال تکنيک هاي داده کاوي) در فرآيند وب کاوي مي باشد.
به طور کلي دو گونه متفاوت از استخراج اطلاعات وجود دارد. استخراج اطلاعات از متون غير ساخت يافته و استخراج اطلاعات از داده هاي نيمه ساخت يافته. براي استخراج اطلاعات از متون غير ساخت يافته معمولا نوعي پيش پردازش زباني قبل از به کارگيري تکنيک هاي داده کاوي استفاده مي شود. بنابراين اين نوع از استخراج اطلاعات ارتباط نزديکي با تکنيک هاي پردازش زبان طبيعي دارد. اما با ايجاد و گسترش وب نياز به روش هاي بازيابي اطلاعات از متون ساخت يافته مي باشد. استخراج اطلاعات ساخت يافته متفاوت از استخراج اطلاعات غير ساخت يافته است، چرا که معمولا از اطلاعاتي مانند تگ هايHTML، جدا کننده ها، … استفاده مي کند. بيشتر روش هاي ساخت يافته اي که در وب به کار مي روند، از تکنيک هاييادگيري ماشين براي استخراج قوانين استفاده مي کنند.
وب کاوي معادل يادگيري از وب يا به کارگيري تکنيک هاييادگيري ماشين در وب نيست. کاربردهايي از يادگيري ماشين در وب وجود دارد که نمونه هاي وب کاوي به شمار نمي آيند. يک مثال از اين نوع کاربردها، به کارگيري تکنيک هاييادگيري ماشين براييافتن بهترين مسير در پيمايش وب توسط Spider ها است.
از طرف ديگر علاوه بر تکنيک ها و روش هاييادگيري ماشين، روش هاي ديگري هم براي وب کاوي به کار مي رود. به عنوان مثال الگوريتم هايي اختصاصي براييافتن Hub ها وAuthority ها در وب وجود دارد. با اين حال ارتباط نزديکيبين يادگيري ماشين و وب کاوي وجود دارد. در واقع تکنيک هاييادگيري ماشين از وب کاوي پشتيباني مي کنند و قابل استفاده در فرآيندهاي وب کاوي مي باشند. به عنوان مثال تحقيقات نشان مي دهد استفاده از تکنيک هاييادگيري ماشين در طبقه بندي اسناد، مي تواند دقت طبقه بندي را در مقايسه با استفاده از روش هاي سنتي بازيابي اطلاعات افزايش دهد.
روش هاي وب کاوي بر اساس آن که چه نوع داده اي را مورد کاوش قرار مي دهند، به سه دسته تقسيم مي شوند:
- کاوش محتواي وب[42]: کاوش محتواي وب فرآيند استخراج اطلاعات مفيد از محتواي مستندات وب است. محتواييک سند وب متناظر با مفاهيمي است که آن سند در صدد انتقال آن به کاربران است. اين محتوا مي تواند شامل متن، تصوير، ويدئو، صدا و يا رکوردهاي ساخت يافته مانند ليست ها و جداول باشد. در اين ميان کاوش متن بيش از ساير زمينه ها مورد تحقيق قرار گرفته است. از جمله اين تحقيقات مي توان به تشخيص موضوع[43]، استخراج الگوهاي ارتباط[44]، خوشه بندي[45] و طبق بندي اسناد وب اشاره کرد. روش ها و تکنيک هاي موجود در اين گروه، از تکنيک هاي بازيابي اطلاعات و پردازش زبان طبيعي نيز استفاده مي کنند.
هر چند در پردازش تصوير و بينايي ماشين تحقيقات زيادي در زمينه استخراج دانش از تصاوير انجام شده است، اما به کارگيري اين تکنيک ها در کاوش محتواي وب چندان چشمگير نبوده است.
- کاوش ساختار وب[46]: وب را مي توان به صورت گرافي که گره هاي آن اسناد و يال هاي آن پيوندهاي[47] بين اسناد است، بازنمايي کرد. کاوش ساختار وب، فرآيند استخراج اطلاعات ساختاري از وب مي باشد.
- کاوش استفاده از وب[48]:کاوش استفاده از وب، کاربرد تکنيک هاي داده کاوي براي کشف الگوهاي استفاده از وب، به منظور درک و برآوردن بهتر نيازهاي کاربران مي باشد. اين نوع از وب کاوي، داده هاي مربوط به استفاده کاربران از وب را مورد کاوش قرار مي دهد.
بايد توجه داشت که مرز مشخصي ميان سه گروه وب کاوي وجود ندارد. به عنوان مثال تکنيک هاي کاوش محتواي وب مي توانند علاوه بر به کارگيري متن مستندات، از اطلاعات کاربران هم استفاده کنند. همچنين مي توان از ترکيب تکنيک هاي فوق براي حاصل شدن نتايج بهتر استفاده کرد.
وب کاوي با چالش ها و محدوديت هاي متنوعي روبه رو است. از يک ديدگاه مي توان اين محدوديت ها را به دو گروه تکنيکي و غير تکنيکي تقسيم کرد. از محدوديت هاي غير تکنيکي مي توان به عدم پشتيباني مديريت، کافي نبودن بودجه و عدم وجود منابع مورد نياز مانند نيروي انساني متخصص اشاره کرد. اما مشکلات تکنيکي بسيار است که به برخي از آنها در اين جا اشاره مي شود:
- داده هاي ناصحيح و نادقيق : براي آن که فرآيند وب کاوي با موفقيت انجام شود، لازم است داده هاي جمع آوري شده صحيح و در قالب مناسب باشند. اما معمولا مشکلات زيادي در اين زمينه وجود دارد. اولا، داده ها ممکن است دقيق نباشند. ثانيا داده ها مي توانند ناکامل بوده و برخي مقادير موجود نباشد. ثالثا تخمين ميزان اطمينان درباره صحت و دقت داده ها به سادگي امکان پذير نيست.
- عدم وجود ابزارها: محدوديت ديگر وب کاوي، عدم وجود ابزارهاي مناسب و کامل براي آن مي باشد. در اين راستا، متخصصان بايد تصميم بگيرند آيا براييک کاربرد از وب کاوي، ابزار خاص آن کاربرد را توسعه دهند و يا از ابزارهاي موجود استفاده کنند.
- ابزارهاي سفارشي: ابزارهاي موجود تنها يکي از انواع وب کاوي مانند طبقه بندييا خوشه بندي را پشتيباني مي کنند. اما بهتر آن است که يک ابزار قادر به انجام چندين تکنيک وب کاوي باشد تا کاربران بتوانند با توجه به نيازمندي هاي خود از تکنيک مناسب استفاده کنند.
البته در حال حاضر تحقيقات بسياري در زمينه وب کاوي در حال انجام است که هدف آن ها حل اين مشکلات مي باشد.
3-6مشكلات ومحدوديت هاي وب كاوي در سايت هاي فارسي زبان
در دهه هاي اخير ، بيشترين اختلاف نظر در باب شيوه املاي كلمات فارسي بر سر موضوع جدانويسي يا پيوسته نويسي كلمات مركب بوده است.فرهنگستان زبان و ادب فارسي ، در اين باب راه ميانه را برگزيده و كوشيده است تا فقط مواردي را كه جدانوشتن و يا پيوسته نوشتن آنها الزامي است ، تحت قاعده و ضابطه درآورد و شيوه نگارش بقيه كلمات مركب را به ذوق و سليقه نويسندگان واگذار كند.بعضي چالش هاي زبان فارسي در رايانه و بخصوص در اينترنت كه باعث تفاوت در نتيجه جستجو در وب يا وب كاوي مي شود از قرار زير است:
الف) تنوع نحوه استفاده از “مي” چسبان و غير چسبان ، مثل كلمات “مي تواند” و “ميتواند”.
ب) تنوع نحوه بكاربردن چسبان و غير چسبان “ها” ، مثل “آن ها” و “آنها”.
ج) بكار بردن بعضي پيشوند ها و پسوند ها ، مثل “همين كه” و “همينكه” ويا “هيچ يك” و “هيچيك” و
يا “راه گشا” و “راهگشا”.
د) بكاربردن “حمزه” بصورت هاي مختلف ، مثل “مسؤول” و “مسئول” يا “مسأله” و “مسئله”.
ه) استفاده يا عدم استفاده از “ء” ، براي كلمات مختوم به هاي بيان حركت ، در حالت مضاف ، مثل “خانة مسكوني” و “خانه مسكوني”.
و) تنوع استفاده از “ي” در كلمات عربي مختوم به “ا” ، مثل “موسي” و “موسا”.
ز) تنوع املايي بعضي كلمات كه همه درست هستند ، مثل “اتاق” و “اطاق”.
ح) استفاده از كلمات اروپايي بصورت زبان اصلي يا ترجمه فارسي بخصوص در متون علمي ، مثل
“Update” و “بروزآوري”.
ط) استفاده يا عدم استفاده از جمع مكسر براي بعضي كلمات.
ي) تبديل كلمات اروپايي به رسم الخط فارسي با همان تلفظ اصلي ، مثل “Source” و “سورس”.
ك) استفاده از “ا” و “آ” بجاي هم ، مثل “فرايند” و “فرآيند”.
ل) استفاده يا عدم استفاده از اعراب براي كلمات .
بعبارت ديگر ، يك كاربر ممكن است در جستجوي خود در وب ، كلمه كليدي خاصي را بكار برد ، ليكن در صفحات وب چنين كلمه اي بكار نرفته باشد و با توجه به مواردي كه در مورد تنوع كاربري كلمات ، بحث شد ،كلمه مشابهي ثبت شده باشد. بنابراين بسياري از صفحات وب مطلوب كاربر ، در مجموعه بازيابي شده ، وجود نداشته باشد
محتواكاوي وب(Web Content Mining) ، يكي از سه شاخه وب كاوي است كه در واقع ، كشف اطلاعات مفيد از مستندات و داده هاي ساختيافته و نيمه ساختيافته و غير ساختيافته وب مي باشد. يك شاخه ديگر اين مقوله ، ساختاركاوي وب(Web Structure Mining) است كه به كشف مدل پشت زمينه حاكم بر ساختار فرا پيوند هاي وب مي پردازد و هدف آن ، ايجاد اطلاعاتي همچون تشابه يا ارتباط بين سايت هاي مختلف وب است. شاخه ديگر آن كاربرد كاوي وب مي باشد كه سعي مي كند از تعاملات كاربربا وب ، اطلاعاتي كسب كند و از آن ها بصورت سابقه اي در مراجعات بعدي كاربر سود ببرد.
در زمينه محتواكاوي وب نرم افزارهاي خزنده(Crawler) ، به گشت و گذار در اقيانوس وب پرداخته ، اقدام به نمايه سازي واژگان در پايگاه داده خود مي نمايند كه مورد استفاده موتورهاي كاوش ، در زمان جستجوهاي كاربر قرار مي گيرد. نمونه بارز اين روش ، موتور كاوشگر Google است.در همين راستا ابزارهايي همچون FASTUS:Finite-State Automaton Text Understanding System ، در خلال اين ماموريت به تجزيه و تحليل متون ، با هدف كشف گروه هاي مختلف واژگان مانند اسامي ، افعال ، تركيبات وصفي و اضافي ،… مي پردازند كه به كشف دانش از محتويات وب كمك مي كند. اين روش هم اكنون براي زبان هاي انگليسي و ژاپني پياده سازي شده است وبصورت بالقوه براي ديگر زبان ها قابل استفاده است
از طرف ديگر استفاده از آنتولوژي(Ontology) در وب در بهينه سازي كاوش در وب پيشنهاد مي گردد. آنتولوژي ، يك فرهنگ واژگان مشترك بر اساس موضوع سايت براي استاندارد سازي ارائه مفاهيم آن جهت قابل تفسير شدن توسط ماشين ، تعريف مي كند. آنتولوژي ، يك جزء كليدي وب مفهومي است.
شخصي كردن وب(Personalization) ، از ديگر روش هاست كه در امر كاوش وب مثمر ثمر است. نمونه اين روش در My Yahoo قابل مشاهده است.
يكي ديگر از راه هاي كاوش در مقدار زياد و غير ساختيافته اطلاعات وب ، استفاده از پايگاه داده چند لايه اي (MLDB) است. هر لايه از اين پايگاه داده ، تعميم بيشتري از لايه قبلي است. همه لايه ها بجز پايين ترين لايه (كه خود وب است) ، قابل كاوش توسط يك زبان پرس وجو مثل SQL است.در پياده سازي روش هاي ساختاركاوي وب ، از تئوري گراف وب بهره مند خواهيم شد كه به ايجاد ديد ارزشمند در الگوريتم هاي جستجو ، كشف ارتباطات ،… موثر است.در خصوص روش هاي كاربرد كاوي وب ، ناوبري كاربر در وب توسط مدل هاي رياضي ماركو(Markov) ، براساس ميزان تجربه كاربر و دارا بودن يا عدم داشتن راهنماي سايت ، تجزيه و تحليل مي گردد.
فصل چهارم
وب کاوی در صنعت
4-1-1وب کاوی در صنعت نفت، گاز و پتروشیمی
با توجه به آنکـه داده كـاوی فرآیندی اسـت كه از انواع تكنیك های مدل سازی و آنالیـز داده برای كشـف الگـوها و ارتبــاطات در داده ها برای انجام پیش بینی های دقیق بهره می برد، این امر صنعت نفت را در موضوعات متنوعی یاری می دهد. امروزه حجم انبوه داده های مشتریان و تعاملات پیچیده فزاینده با آنان، دادهکاوی را به صف مقدم سودآور كردن ارتباطات با مشتری سوق داده است بگونه ای که استفاده از روش های جدید آنالیز داده مانند داده كاوی برای پایگاه های داده این صنعت بسیار حیاتی بوده و بدین جهت امروزه دانش داده کاوی در تمامی موضوعات و برنامه ریزی های خرد و کلان صنعت نفت نقشی موثر ایفا می نماید. از جمله کاربرد های داده کاوی در صنایع نفتی می توان به موارد ذیل اشاره کرد :
آنالیز داده های چاه آزمایی
آنالیز داده های فشار و دبی بدست آمده از فشارسنج های دائم درون چاهی
مدلسازی و توصیف مخزن
آنالیز داده های لرزه نگاری
شناسایی و دسته بندی رخساره ها
تخمین میزان رسوب
تعیین نوع و کیفیت تخلخل سنگ مخزن
آنالیز داده های سنجش از راه دور (RemoteSensing)
ساخت نمودارهای پتروفیزیکی مصنوعی
بهینه سازی مكان چاهها
شبیه سازی دینامیك مخزن
تجمیع داده ها
تطابق تاریخچه
تخمین میزان بهره دهی مخازن
مدلسازی شبكه منافذ سنگ مخزن
تخمین پارامترهای سیال مخزن
طراحی فرآیندهای ازدیاد برداشت نفت
تخمین میزان آسیب سازندی
بهینه سازی فرآیند فرازآوری با گاز
آنالیز داده های تولید
بهینه سازی تولید
تعیین رژیم جریانی چندفازی درون خطوط لوله
آنالیز گرهی
تخمین نرخ نفوذ در عملیات حفاری
پیش بینی احتمال گیر لوله ها حین عملیات حفاری
تشخیص و پیشگیری از وقوع فوران چاه
مدیریت منابع
مدیریت داده ، نگهداری ، تعمیرات
بازاریابی
مدیریت مشتریان
تامین مواد
مدیریت انتخاب تامین کنندگان
کنترل پروژه
مدیریت مراکز فروش و توزیع کنندگان
ارزیابی عملکرد
مدیریت کیفیت
4-1-2 کاربرد های دانش داده کاوی در صنعت بیمه
صنعت بیمه در کشورهای توسعه یافته از جمله کاربران اصلی دانش نوین داده کاوی و پیشروان بهره گیری از این دانش نوین می باشند بگونه ای که امروزه این دانش در تمامی عرصه های این صنعت از جمله :
- بخش بندی مشتریان
- تعیین میزان ریسک و میزان حق بیمه مشتریان
- مدیریت ارتباط با مشتریان
- تعیین ارزش عمر مشتریان
- هدف گذاری مشتریان با ارزش
- طراحی محصولات ترکیبی بیمه ای
- جایابی و برنامه ریزی ایجاد شعب جـدید
- برنامه ریزی ارتقاء سـطح رضایتمندی کارکنان و مشتریان
- کشف تقلب و کلاهبرداری
- پیشبینی بـازار رقابتـی
- برنامه ریزی تبلـیغات و بازاریابی
- ارزیابی شعب و کارکنان
- برنامه ریزی و مدیریت منابع انسانی
و بسیاری دیگر از مقولات مرتبط با صنعت بیمه دارای کاربرد فراوان است. داده كـاوي فرآيندي اسـت که موسسات بیمه ای را در موضوعات متنوعی یاری داده و بدین جهت امروزه دانش داده کاوی در تمامی موضوعات و برنامه ریزی های خرد و کلان موسسات بیمه نقشی موثر ایفا می نماید.
4-1-3کاربردهای دانش داده کاوی در مدیریت شهری
یکی از مهمترین کاربردهای دانش داده کاوی، در حوزه ی مدیریت شهری است. امروزه دادهکاوی، مدیریت شهری را در موضوعات متنوعی یاری داده بگونه ایکه استفاده از این دانش به عنوان جدیدترین و برترین روش حل مسئله براي پايگاه هاي داده مدیریت شهری بسيار حياتي بوده و بدین جهت امروزه دانش داده کاوی در تمامی موضوعات و برنامه ریزی های خرد و کلان مدیریت شهری نظیر
- برنامه ریزی شهری
- حمل و نقل و ترافیک
- زیباسازی
- خدمات شهری
- مدیریت پسماند
- مهندسی فرهنگی شهری
- ارتباط با شهروندان
- ارائه خدمات اضطراری
- ایجاد خدمات و تسهیلات جدید
- برنامه ریزی ارتقاء سطح رضایتمندی شهروندان
4-1-4کاربردهای داده کاوی در صنعت بانکداری
صنعت بانکداری در کشورهای توسعه یافته از جمله کاربران اصلی دانش نوین داده کاوی و پیشروان بهره گیری از این دانش می باشند بگونه ای که امروزه این دانش در تمامی عرصه های این صنعت از جمله :
- برنامه ریزی ارتقا سـطح رضایتمندی کارکنان و مشتریان
- اعتبار سنجی مشتریان
- کشف تقلب و کلاهبرداری
- مدیریت ارتباط با مشتریان
- پیش بینی بـازار رقابتـی
- تعیین ارزش عمر مشتریان
- برنامه ریزی تبلـیغات و بازاریابی
- هدف گذاری مشتریان باارزش
- ارزیابی شعب و کارکنان
- جایابی و برنامه ریزی ایجاد شعب جـدید
- برنامه ریزی و مدیریت منابع انسانی
با توجه به آنکه داده كاوي فرآيندي اسـت كه از انواع تكنيك هاي مدل سازي و آناليز داده براي كشـف الگوها و ارتبـاطات در داده ها براي انجام پيش بيني هاي دقيق بهره مي برد، اين امر بانک ها را در موضوعات متنوعی یاری می دهد. امروزه حجم انبوه داده های مشتريان و تعاملات پيچيده فزاينده با آنان، دادهکاوی را به صف مقدم سودآور كردن ارتباطات با مشتري سوق داده است بگونه ای که استفاده از دانش جديد داده كاوي به عنوان جدیدترین و برترین روش حل مسئله براي پايگاه هاي داده اين صنعت بسيار حياتي بوده و بدین جهت امروزه دانش داده کاوی در تمامی موضوعات و برنامه ریزی های خرد و کلان بانک ها و موسسات مالی و اعتباری نقشی موثر ایفا می نماید.
امروزه صنایع و تولیدکنندگان در کشور در حال رقابت با همتایان خود در آن سوی آّبها هستند. از سوی دیگر در هر یک از این صنایع، حجم انبوهی از داده ها، تولید و ذخیره می شود و کمترین استفاده ممکن از آنها صورت می گیرد. بخش های فروش، بازاریابی، تولید، نگه داری و تعمیرات، مالی، منابع انسانی، انبار، ایمنی، مدیریت و … همگی داده های زیادی تولید می کنند که با به کارگیری داده کاوی صنعت، معدن و تجارت قادر خواهد بود توسعه ی خود در فضای رقابت را حفظ کند.
- برنامه ریزی نگهداری و تعمیرات
- انتخاب تأمین کنندگان
- مدیریت انبار مواد و قطعات یدکی
- طراحی محصولات جدید
- مدیریت کیفیت و بهره وری
- برنامه ریزی و مدیریت منابع انسانی
- بازاریابی و تبلیغات
- مدیریت ارتباط با مشتریان
- لجستیک و ترابری
- اکتشاف معادن
- بخشبندی مشتریان
- بازرگانی هوشمند
سایر بخش ها: مدیریت انرژی، ایمنی، محیط زیست، مدیریت ریسک، مدیریت مالی
با ايجاد و گسترش وب و افزايش چشمگير حجم اطلاعات، روش ها و تکنيک هايي براي استفاده از اين اطلاعات و استخراج اطلاعات جديد از آنها مورد نياز مي باشد. روش هاي سنتي بازيابي اطلاعات که براي جستجوي اطلاعات در پايگاه داده ها به کار مي روند، قابل استفاده در وب نمي باشند. وبکاوي که به کارگيري تکنيک هاي داده کاوي براي کشف و استخراج خودکار اطلاعات از اسناد و سرويس هاي وب مي باشد، می تواند برای اين منظور به کار رود.
وب کاوي شامل چهار مرحله اصلي پيدا کردن منبع، انتخاب اطلاعات و پيش پردازش، تعميم، تحليل می باشد. روش هاي وب کاوي بر اساس آن که چه نوع داده اي را مورد کاوش قرار مي دهند، به سه دسته تقسيم مي شوند: کاوش محتواي وب، کاوش ساختار وب کاوش استفاده از وب.
تکنيکها و روشهاي وب کاوي از کاربرد وسيعي در حوزههاي مختلف همچون تجارت الکترونيکي، دولت الکترونيکي، آموزش الکترونيکي، آموزش از راه دور، سازمان هاي مجازي، مديريت دانش، کتابخانههاي ديجيتال برخوردارند. البته وب کاوي با چالش ها و محدوديت هاي متنوعي روبه رو است و در حال حاضر تحقيقات بسياري در زمينه وب کاوي در حال انجام است که هدف آن ها حل اين مشکلات ميباشد.
دانشنامه آزاد ویکی پدیا
ماهنامه عملی آموزشی تدبیر شماره 156
مهريزي، حائري، علي اصغر ، «دادهكاوي: مفاهيم، روشها و كاربردها» (1382) پاياننامه كارشناسي ارشد آمار اقتصادي و اجتماعي، دانشكده اقتصاد، دانشگاه علامه طباطبائي.
زعفريان، رضا و زعفريان،قاسم، «مروري بر دادهكاوي» (1380) فصلنامه صنايع، شماره 29
شاهسمندي، پرستو «دادهكاوي در مديريت ارتباط با مشتري» (1384)، مجله تدبير شماره 156.
گودرزي، حميدرضا، مترجم «دادهكاوي چيست»، نشريه گزيده مطالب آماري، مركز آمار ايران، شماره 52.
جمالي، آرمان – شهر الكترونيكي، بستر ورود به رقابتهاي عصر سيبرنتيك
مراجع و ماخذ لاتین و سایتهای اینترنتی
Barbara Mento and Brendan Rapple, SPEC Kit 274: Data mining and data warehousing, Association of Research Libraries, Washington, DC (2003, July)
http://www.ece.ut.ac.ir/dbrg/index.htm
http://www.irandoc.ac.ir/index.htm
http://www.arts.uci.edu/dobrain/gems.980415b.htm
- Query ↑
- Precision ↑
- Recall ↑
- Personalization ↑
- Web Mining ↑
- Data Mining ↑
- Data warehouses ↑
- Knowledge-based system ↑
- Knowledge-acquisition ↑
- Information retrieval ↑
- High-performance computing ↑
- Data visualization ↑
- Knowledge Discovery in Database ↑
- Secondary Data Analysis ↑
- Knowledge base ↑
- Mining ↑
- Knowledge extraction ↑
- Data archaeology ↑
- Data dredging ↑
- Spread sheets ↑
- Artificial Intelligence ↑
- Machine Learning ↑
- Text Mining ↑
- Web Mining ↑
- Decision Support Tools ↑
- Input Layer ↑
- Hidden Layer ↑
- Output Layer ↑
- Training method ↑
- Epoch ↑
- Generalization ↑
- Validation ↑
- Stemming ↑
- Stop Words ↑
- Knowledge Discovery in Data Base ↑
- Data Warehouse ↑
- Privacy ↑
- Indexing ↑
- Classification ↑
- Data Visualization ↑
- Filtering ↑
- Web Content Mining ↑
- Topic Discovery ↑
- Association Pattern ↑
- Clustering ↑
- Web Structured Mining ↑
- Hyperlink ↑
- Web Usage Mining ↑